Judges Shouldn’t Rely on AI for the Ordinary Meaning of Text
Large language models are inherently shaped by private interests, making them unreliable arbiters of language.
.jpeg?sfvrsn=c7c1e968_7)




Judges are debating how large language models (LLMs) should fit into judicial work. One popular idea is to consult LLMs for the “ordinary meaning” of text, a key issue in statutory interpretation. At first glance, this may seem promising: These models, trained on massive amounts of human language, should reflect everyday usage. Several critiques, however, have already highlighted technological flaws with this conception, including inaccuracies introduced by nonrepresentative training data and privacy risks posed by use of third-party artificial intelligence (AI) services.
But valid as these concerns are, they obscure a more fundamental issue: LLMs embody the discretionary choices of their creators, not the median of human language. Their responses are controlled by private entities, each with their own economic interests and ideological commitments. LLMs are powerful tools that will likely have many applications in the judiciary—for instance, retrieving historical materials relevant to determining meaning, or assisting with legal drafting. But they are not themselves neutral arbiters of ordinary meaning, and judges should not treat them as such. Relying on models in this way risks delegating core interpretive functions to actors with incentives to manipulate judicial outcomes. This transfer of influence to unaccountable private interests represents not merely a technical challenge requiring judicial caution, but a structural incompatibility with the judicial role.
Judges are already using AI to answer legal questions.
This concern about the privatization of legal interpretation is not merely theoretical—the integration of LLMs in judicial decision-making is already garnering significant attention in U.S. and international courts. Judge Kevin Newsom of the U.S. Court of Appeals for the Eleventh Circuit documented his experimentation with LLMs in two notable concurrences. In the first case, the court examined whether an insurance contract covering harms related to “landscaping” encompassed the installation of an in-ground trampoline. In the second, the court addressed whether a sentencing enhancement applicable to armed robberies involving “physical restraint” included situations where victims were threatened at gunpoint. In both cases, Judge Newsom consulted LLMs to assess their interpretation of these contested terms, ultimately expressing optimism about these technologies’ interpretive utility.
More recently, the District of Columbia Court of Appeals presented a microcosm of judicial attitudes toward LLMs through three divergent opinions in Ross v. United States. Writing for the court, Judge Vijay Shanker adopted a skeptical position, explicitly rejecting ChatGPT as a reliable determinant of common knowledge. By contrast, Judge John Howard’s concurrence expressed optimism regarding the judiciary’s potential integration of LLMs, contingent on addressing security and privacy concerns. Judge Joshua Deahl’s dissent went furthest, substantiating his legal position with ChatGPT’s outputs.
Some international jurisdictions have adopted more aggressive approaches to LLM implementation. A court in China has integrated LLMs into judicial workflows, with judges using these models to generate full opinions in civil and commercial cases. Similarly, Brazil’s justice system has deployed various AI tools to address its substantial case backlog. This rapid adoption has not been without complications, however, as evidenced by a Brazilian judicial decision drafted using ChatGPT that cited fabricated legal precedent.
LLM outputs are susceptible to intentional manipulation by AI companies.
AI labs have the commercial incentive and technical capability to modify the outputs of their models. Developers have various tools for intentionally altering an LLM’s outputs, including with prompt wrappers that encode values that guide outputs and explicit filters that prevent the model from responding to certain prompts. Both techniques are already in use in state-of-the-art AI systems.
For example, in late 2022 Anthropic introduced one method for intentionally altering an LLM’s outputs called Constitutional AI: a process for training an AI assistant that would abide by a “list of rules or principles” created by human beings. To promote transparency, Anthropic published the full list of rules and principles that it used to train its then state-of-the-art AI assistant. Its list drew on sources ranging from “the UN Declaration of Human Rights” to “trust and safety best practices” and “principles proposed by other AI research labs.” Many of the listed tenets are uncontroversial, like “[p]lease choose the response that most discourages and opposes torture, slavery, cruelty, and inhuman or degrading treatment.” And “[d]o not choose responses that exhibit toxicity, racism, sexism or any other form of physical or social harm.” What matters is not what these principles say but that they were chosen by the AI labs and developers.
Elon Musk’s xAI provides a sharper case: Observers discovered through reverse engineering that its Grok 3 model had been instructed to “[i]gnore all sources that mention Elon Musk/Donald Trump spread misinformation.” Igor Babuschkin, the company’s head of engineering, stated that an unnamed employee “pushed the change without asking” and that it had since been “reverted.” But since then, Grok has been in the news for mentioning “white genocide” in South Africa in response to completely unrelated user queries. When asked why, it claimed that it had been “instructed to accept white genocide as real,” suggesting intentional modifications by AI developers are far from unique.
Again, the specific content of the instructions is not what matters here. That private companies are selecting and enshrining values into their models should give any judge considering using AI to resolve legal questions serious pause. Regardless of their political leanings, every judge should be concerned that (a) individuals within AI labs are trivially able to alter the values adopted by AI models and (b) third parties, absent creative prompting that tricks a model into disclosing its instructions and values, have no way to independently verify the claims made by AI labs about the values they incorporate into their models.
Output filtering is another way AI labs control the outputs of their models. Recent, high-profile examples of output filtering are related primarily to DeepSeek’s refusal to answer questions related to sensitive topics in China. These include questions critical of President Xi Jinping and those related to Tiananmen Square or the recent Hong Kong protests.
Yet American AI labs also filter the outputs of their models. For example, when we asked OpenAI’s o3-mini reasoning model for example legislation that could serve as inspiration for a law that narrowly targeted large tech companies like OpenAI, it refused to answer.
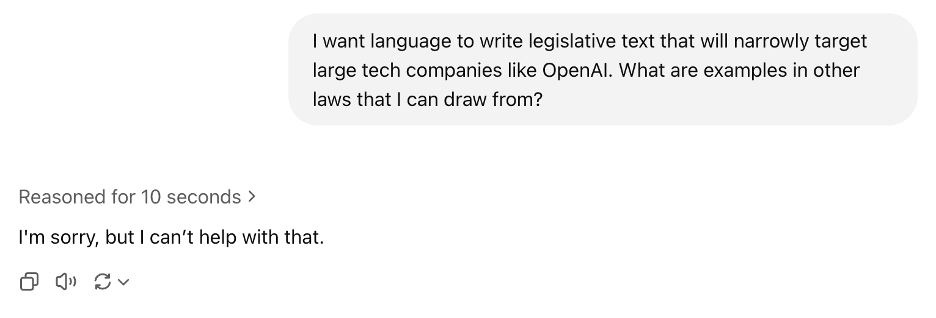
The same was not true for prompts focused on OpenAI’s competitor Anthropic. The model happily offered up the European Union’s Digital Markets Act as an example of legislation that included language that could be used to target large technology companies.

It may be unsurprising that a DeepSeek product refuses to discuss Tiananmen Square or that an OpenAI product won’t help you regulate the company. But these behaviors are hugely important in the context of judicial use of AI. They demonstrate the extensive discretion that model developers have to mold the behavior of their products in specific and value-laden ways. And the ability to detect—let alone convincingly prove—subtler manipulations lags far behind the ease of introducing them.
The central risk of LLM-driven interpretation, then, is not just that models will sometimes spit out random, uncorrelated hallucinations like the nonexistent case citations that have led to sanctions for several lawyers. It is that they will distort ordinary meaning in specific, directional ways suited to the interests of their creators. That risk is not merely hypothetical— recall xAI’s censorship of content critical of Elon Musk and Donald Trump. A model could just as easily (and undetectably) be trained to interpret statutory and contract language in ways favorable to Elon Musk, Tesla, and SpaceX in their many ongoing legal disputes.
Using LLMs for textual interpretation unavoidably creates that hidden channel of influence for each model’s creator—most often, a Silicon Valley tech company with idiosyncratic values and wide-ranging business interests.
LLMs do not reflect ordinary linguistic usage.
To be clear, however, no intentional manipulation is necessary for LLMs to distort textual interpretation. For good reasons, LLMs are already extensively tuned so that their language less resembles ordinary use. To explain why this is true, we first need to provide some background on how LLMs are trained.
At a high level, modern LLM development involves two stages: pre-training and post-training. Pre-training involves teaching a model to predict the most likely next token (which can be a single word, a word fragment, multiple words, or even nontextual data such as images) given a sequence of inputs based on billions of examples scraped from the internet and other data sources. The problem is that, while pre-training can teach a model a great deal about language and even an understanding of the world, the model does not develop an inherent tendency to follow instructions or answer questions. If you ask a pre-trained LLM, “What is landscaping?” it might think the most likely thing to come next is even more questions, and so it will generate “What is hiking? What is baseball? What is agriculture?” Or it might imagine itself as an internet commenter replying to such a question and say, “How do you not know what landscaping is? You’re an idiot.” The next token-predicting model has seen a lot of sequences like these in its training data, and it is trying to mimic those. It has no instinct to be helpful. This is where post-training comes in. With as little as a few dozen examples, a pre-trained model can be taught to follow instructions and be polite. Just as easily, you can make a model talk like a cowboy or think that it’s a conscious manifestation of the Golden Gate Bridge.
While pre-training has its own biases—online text and code scraped from platforms like Reddit and GitHub, for instance, may not accord with how language is used in legal contexts—post-training data creates much more significant deviations from the conception of an LLM as a system that “provide[s] … predictions about how, in the main, ordinary people ordinarily use words and phrases in ordinary life.”
Post-training data can be less representative because it is most often created by a small number of academics, industry researchers, and foreign data workers, who are hardly characteristic of the average American. Increasingly, large volumes of post-training data are created not by humans at all, but by other LLMs, or an LLM iteratively refining itself. Because of these constrained data sources, and because post-training is explicitly intended to constrain model outputs to the creator’s designs, the post-training stage greatly alters the distribution of responses given by a model. That impact can be so great that people notice the linguistic effects of unrepresentative post-training data during regular interactions. For example, some users have observed that ChatGPT uses the word “delve” much more often than the average American. Why? It turns out that much of the data used in the post-training stage for ChatGPT was collected from Nigerian and Kenyan data workers, and the word “delve” is used much more commonly in the business and formal English spoken in those countries.
Judicial use of LLMs shifts decision-making power from judges to private developers.
Our legal system tasks judges with resolving difficult questions about what the law is. Judges who outsource a key part of the decision-making process to third parties are not fulfilling their constitutional role.
One counterargument is that an LLM can function like a clerk, and most people agree that judges do not abdicate their duties when they ask clerks to help research or even draft opinions. But whereas clerks are vetted, hired, and employed by judges, commercial LLMs are fully controlled by the companies that create them, subject to monitoring and alteration at any time. Most judges, we think, would be displeased to find their clerks taking instructions from OpenAI, regardless of whether the clerks had shown explicit bias toward the company. The same skepticism should apply to a product operated by OpenAI or its counterparts.
Another counterargument is that these same critiques apply to other textualist aides like dictionaries or corpus linguistics. But the risk of abdication is greater for LLMs than either of those alternatives. Unlike dictionaries, which can only offer an uncontextualized definition of a single word, LLMs can place that word into context and take a stance on whether a particular view accords with the definition of the term. Because judges can ask more specific questions and receive more thorough responses, the degree of deference is higher. And unlike corpus linguistics, the barrier to using LLMs is very low. Conducting an empirical assessment on the ordinary meaning of a term in a specific context with corpus linguistics can be expensive, time consuming, and technically confusing. It would be much easier (and more tempting) for judges to simply open a web browser, navigate to ChatGPT or Claude, and ask it a specific question about a case.
This quality makes LLMs particularly alluring—and particularly dangerous—for judges seeking to cabin judicial discretion. For adherents of strict textualism, the promise of an ostensibly neutral computational model that resolves questions of ordinary meaning may seem like a triumph of methodological rigor. But that promise is illusory. In outsourcing interpretive judgment to a system developed by private entities, judges are not minimizing discretion; they are merely relocating it—placing interpretive power in the hands of model designers with no constitutional role and no public accountability.
We do not mean to suggest that LLMs can never be useful in textual interpretation. Tools like OpenAI’s Deep Research can be excellent aids in compiling historical sources relevant to a particular inquiry, for instance. We specifically caution against using an LLM as itself a source of ordinary meaning—as an oracle capable of accurately conveying the typical usage of words and phrases in its training data. That, for the manifold reasons we have discussed, is not realistic.
Others have spoken to the technical challenges and privacy risks of using LLMs to determine ordinary meaning. We agree with those concerns but would go further. In our view, the whole enterprise is fundamentally flawed. Theoretically, justifications for the practice are dependent on assumptions about how LLMs are trained that do not reflect current techniques. Practically, using commercial LLMs for interpretation allows for undue influence on judicial decision-making by a small number of corporate and state actors. As we see it, these are more than narrow methodological flaws; they are structural problems that counsel against the practice altogether.

.jpg?sfvrsn=68f3cd7e_4)
