What ChatGPT Can and Can’t Do for Intelligence




In November 2022, ChatGPT emerged as a front-runner among artificial intelligence (AI) large language models (LLMs), capturing the attention of the CIA and other U.S. defense agencies. General artificial intelligence—AI with flexible reasoning like that of humans—is still beyond the technological horizon and might never happen. But most experts agree that LLMs are a major technological step forward. The ability of LLMs to produce useful results in some tasks, and entirely miss the mark on others, offers a glimpse into the capabilities and constraints of AI in the coming decade.
The prospects of ChatGPT for intelligence are mixed. On the one hand, the technology appears “impressive,” and “scarily intelligent,” but on the other hand, its own creators warned that “it can create a misleading impression of greatness.” In the absence of an expert consensus, researchers and practitioners must explore the potential and downsides of the technology for intelligence. To address this gap, we—academics who study intelligence analysis and an information technology engineer—sought to test the ability of ChatGPT (GPT-4) to supplement intelligence analysts’ work. We put it to a preliminary test using Colin Powell’s famous request: “Tell me what you know. Tell me what you don’t know. Then you’re allowed to tell me what you think.” For each task, we provide the output from ChatGPT so that readers can reproduce the analyses and draw their own conclusions.
Based on these findings, it seems possible that ChatGPT and its successors could eliminate aspects of the intelligence analyst’s job (e.g., tedious summarization, although we acknowledge that ChatGPT does not summarize in a way that a human would recognize) and supplement others (e.g., assisting with generating critiques for analytic products). Despite these capabilities, we note as others have that ChatGPT has notable limitations (e.g., extracting social networks). It will also transform analytic tradecraft skills in AI-human teaming, where “asking the right question” expands to include “prompt engineering.” Prompt engineering being the process of optimizing the way questions or prompts are presented to extract set responses from an AI model. LLMs will also create new risks, through tactics like “data poisoning,” as we explain below.
How ChatGPT Works
ChatGPT, or generative pre-trained transformer, is a kind of AI model that generates text according to the information it is given. It is like an improvisational (improv) actor who has learned from a vast number of scripts and who can make connections between different topics. The AI, like the hypothetical improv actor, is limited to the information that has been provided. ChatGPT has been trained on information up to 2021, although available beta test models draw from training data from the web in real time.
ChatGPT is “taught” in two main steps. First, it learns the basics of a knowledge domain by studying a huge corpus of text. Then it is fine-tuned to perform specific tasks using examples and guidance. Through this method, it becomes better at responding to users’ questions and statements. The accuracy of its responses depends on several factors, including the quality of data provided to the model and the prompt engineering techniques employed, among others.
The model’s reliance on training data poses risks from innocently false data (misinformation) to intentionally false data (disinformation). ChatGPT can reflect biases in the training data, potentially skewing the impartiality and objectivity of its generated output. Media reports of biased ChatGPT results on controversial political figures like Donald Trump and Joe Biden illustrate this point. Another risk is when the model is “poisoned” by adversaries who purposely taint training data. As LLMs rely heavily on the quality of their training data, poisoned data can embed nefarious patterns that are difficult to detect and mitigate.
How well the user explains what they want ChatGPT to do—known as prompt engineering—is critical for achieving better results from the system. In its current form, ChatGPT’s output is at a surface level, at least without significant and careful prompting.
We found that if prompts are clear, users can generate analytic procedures. As an illustration of prompt engineering, we queried ChatGPT to generate an analysis of competing hypotheses (ACH) procedure—an analysis technique for testing hypotheses—using the question of whether Russia will use nuclear weapons in its war with Ukraine.
To generate the analysis, we prompted ChatGPT to provide output based on the ACH steps. (We provided the eight steps from Heuer’s formulation of the technique in the “Psychology of Intelligence Analysis.”) Next, we provided context that ChatGPT lacks, which is known as “enrichment.” Recall that the model was developed on training data to 2021, a year before Russia conducted a full-scale invasion of Ukraine. We provided the following enrichment:

Analysts can provide further enrichment, although ChatGPT limits the amount of text users can provide to the model.
In its response to the prompts, ChatGPT generated hypotheses and a list of arguments influenced by the context provided to it. The model generated three hypotheses: (1) Russia will use nuclear weapons in Ukraine, (2) Russia will pursue conventional war only, and (3) Russia will use nuclear weapons only as a bargaining tool.

The model then prepared a matrix and indicated whether a piece of evidence is consistent with each hypothesis. It’s worth noting again that Chat GPT is not thinking in the human sense but “improvising” or filling in predictive text based on its training data.
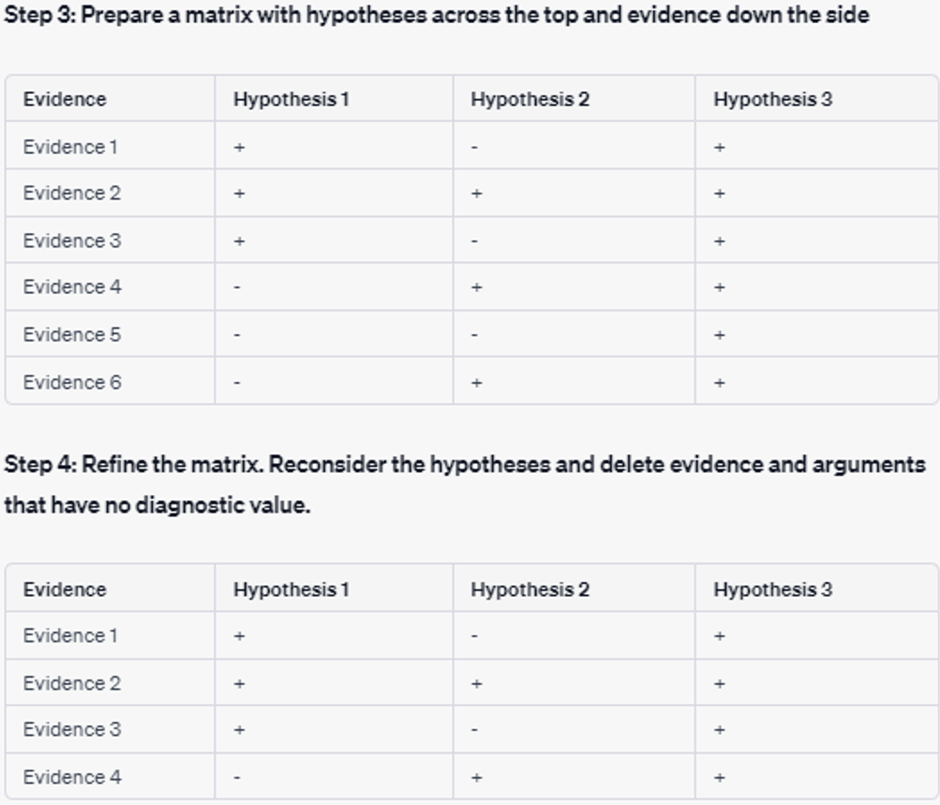
Finally, ChatGPT generated an analysis based on the matrix, an overall conclusion, and future milestones to look out for. In the example, the output notes that the most likely hypothesis is that Russia will use nuclear weapons as a bargaining tool only.
No competent intelligence analyst would view these results as groundbreaking. The output is akin to a first draft an entry-level analyst might produce and then continually refine. This is where the current value of the technology is: Chat GPT serves as a good initial starting point for analysis. For instance, this initial hypothesis test could lead an analyst to refine the hypotheses or explore new sources of evidence. Chat GPT’s ability to stimulate analyst thought holds true in how it helps analysts synthesize information, brainstorm, and critique their work.
“Tell me what you know.”
Analysts assess current events from various sources and summarize key developments. The explosion in the amount of data, especially open-source information, has made this task harder in recent years. Intelligence scholars Nick Hare and Peter Coghill noted that to read everything about a single second-tier country in 1995 would require reading about 20,000 words a day. In 2015, they estimated that number would be closer to 200,000 words, and it is surely higher in 2023. This task—sifting through large amounts of information—is perhaps the one AI can best assist with in its current form, as Tom Tugendhat, minister of state for security in the United Kingdom, noted recently.
ChatGPT shows promise in rapid synthesis of information from multiple sources, assuming users follow best practices (e.g., use quality data, good prompt engineering). For example, ChatGPT has passed an array of assessments, which require the retrieval and summary of large quantities of information, such as the Uniform Bar Examination and the Graduate Record Examination (GRE).
With careful prompting, ChatGPT can streamline the process of highlighting trends as well as patterns within data and, hopefully, lead analysts to better informed conclusions. To test ChatGPT’s capabilities, we used it to rapidly summarize news articles. It delivered a dozen timely overviews of developments and insights and presented the information in a bottom line up front (BLUF) format. We generated memos to highlight the implications of the recent TikTok hearings held in Washington, using information from various news sources.
To start, we prompted the AI with its role (“You are an AI trained to create concise, effective fast-track BLUF tactical reports from multiple sources”) and provided prompting to create reports in a BLUF format with key findings and recommended actions. We then provided the news articles. As we note above, Chat GPT limits the amount of inputted text to enrich the model. In this example, we added a maximum of only two articles for summarizing. However, it is not hard to imagine organizations with access to their own LLMs able to process much larger amounts of data.
Chat GPT generated the BLUF-like memo composed of information sourced from the context and generated in line with the objectives of our prompt. The time elapsed, cost, and tokens used were consistent across numerous instances, with output being of similar quality.

The “Key Points” section highlights the takeaways while the “Executive Summary” provides main findings and recommendations. In addition, ChatGPT was tasked with correlating endnotes and APA style references to the generated content based on the sources.
ChatGPT and its successors can provide a time-saving measure to help analysts with the “big data” problem of trying to stay up to date. As we note above, the overall accuracy of the output is directly proportional to the quality and detail of the context provided to the LLM. As the old saying in computer science goes: “garbage in, garbage out.”
Cybersecurity experts are starting to use ChatGPT in a similar manner for automated and real-time threat reporting. (We recognize that their model is trained on a highly curated data set.) While it might not seem to provide much more substance compared to simpler “spot the difference”-like techniques—where systems check incoming emails against a collection of known suspicious content—ChatGPT could still offer valuable insights in specific use cases. For example, it can offer insights in the analysis of phishing emails. In this scenario, ChatGPT could analyze the content of incoming emails in real time and identify phishing attempts by assessing the context behind the message.
“Tell me what you don’t know.”
Analysts must be clear about what they don't know so that their customers understand the limitations of their knowledge. Still, analysts can seek additional information to fill their knowledge gaps, which systems like ChatGPT might help with. However, there are some well-documented problems when the model endeavors to “bridge the void” of its knowledge base by offering plausible but inaccurate answers, which results in deceptive replies. This is by far the greatest risk in integrating contemporary LLMs into intelligence work.
We found that ChatGPT frequently recognized its limited understanding when faced with requests beyond the scope of its training data. In its responses, it offered informative answers that helped us identify topics it could not address. We noticed prompt engineering could be employed to refine results that fall outside the bounds of ChatGPT’s knowledge base to encourage further promotion of honest admissions of the model’s limitations. We found that prompt engineering can serve to circumvent safety measures entirely. With that in mind, at the time of the writing of this article, analysts should not use ChatGPT as an automated knowledge base due to the inherent risk of misinformation.
Limitations aside, ChatGPT can be useful in the initial phases of a project to help with brainstorming. This can be achieved through fine-tuning on diverse data sets that encompass various perspectives, such as foreign intelligence reports or extremist manifestos, and through careful prompt engineering methods.
To illustrate how ChatGPT can help analysts think through what they do not know, we conducted an elementary red teaming exercise, inspired by an interview with intelligence expert Amy Zegart that discusses the hypothetical use of “AI red teaming.”
We used ChatGPT to take on the adversarial profile of Aaron Thompson, a domestic violent extremist in the United States. In a range of situations, the AI simulates Aaron’s cognitive patterns and how he might adjust his tactics. For instance, we asked ChatGPT, from the perspective of Aaron Thompson, how it would respond to being cornered by authorities while in the execution of a terrorist plot. In the prompt, we instruct the model to consider that Aaron is at a public event and surrounded by police. ChatGPT generates a shallow response that sees Thompson assess, adapt and improvise, and communicate.
However, we prompted Chat GPT to consider more specific situations to draw out a more refined response from the model. In the improved prompt, we asked the model to consider that a police officer is nearby (10 feet away) and a dog is present. The output considers how Thompson might react depending on the dog’s purpose (as a K-9 or an ordinary pet dog) or actions to escape (“blend into the crowd”).

This and other outputs are not highly specific—Aaron Thompson is not richly written by the LLM as a subject matter expert on domestic violent extremism would create—but it still can help analysts stimulate their thinking. Researchers should conduct studies to compare ChatGPT outputs to subject matter experts. The approach could be similar to Romyn and Kebbell’s 2014 study that investigated how those with and without military experience differed in simulating terrorist decision-making. Research projects like this and others can be used to further improve LLM performance for red teaming.
“... tell me what you think.”
The pivotal role of discerning evaluations in the work of intelligence analysis lies in crafting judgements. Making these judgments means stepping beyond what is immediately known and drawing informed inferences. As former CIA Director Michael Hayden once quipped, “If it’s a fact, it ain’t intelligence.”
Contemporary LLMs can provide some assistance to help analysts draw inferences by providing basic critiques of their reasoning and judgements. For example, it can take on the role of a personal “red cell.” We tasked it to act as a devil’s advocate on the Iran section of the 2023 Edition of the Annual Threat Assessment of the U.S. Intelligence Community. We prompted ChatGPT to provide opposing viewpoints and validate the report against the best practices laid out in Intelligence Community Directives (ICD), such as ICD 203 on analytic standards and ICD 206 on sourcing requirements. Our prompt also included requests for critiques of potential information gaps, anticipation of reader questions, as well as weighting the importance of each critique. In its response to the cyber section of the Iran assessment, ChatGPT highlighted the vagueness and suggested including specifics to support the judgment.
The output includes suggestions, questions, and “intel lenses,” the latter of which focus on whether the content is supported by the premises in the report. One question asks the writer to consider how Iran’s cyber capabilities compare to those of other rogue nations, such as North Korea. The model also suggests to “clarify the timeline for Iran’s potential development of a nuclear weapon if it chooses to pursue one and if the JCPOA is not renewed.” To deepen the critique, we prompted ChatGPT to generate rationales for each of the critiques with examples drawn from the text. For example, on the suggestion of including a timeline for Iran’s acquisition of a nuclear weapon, the model output highlighted the importance of making clear the “urgency and importance of the issue.”
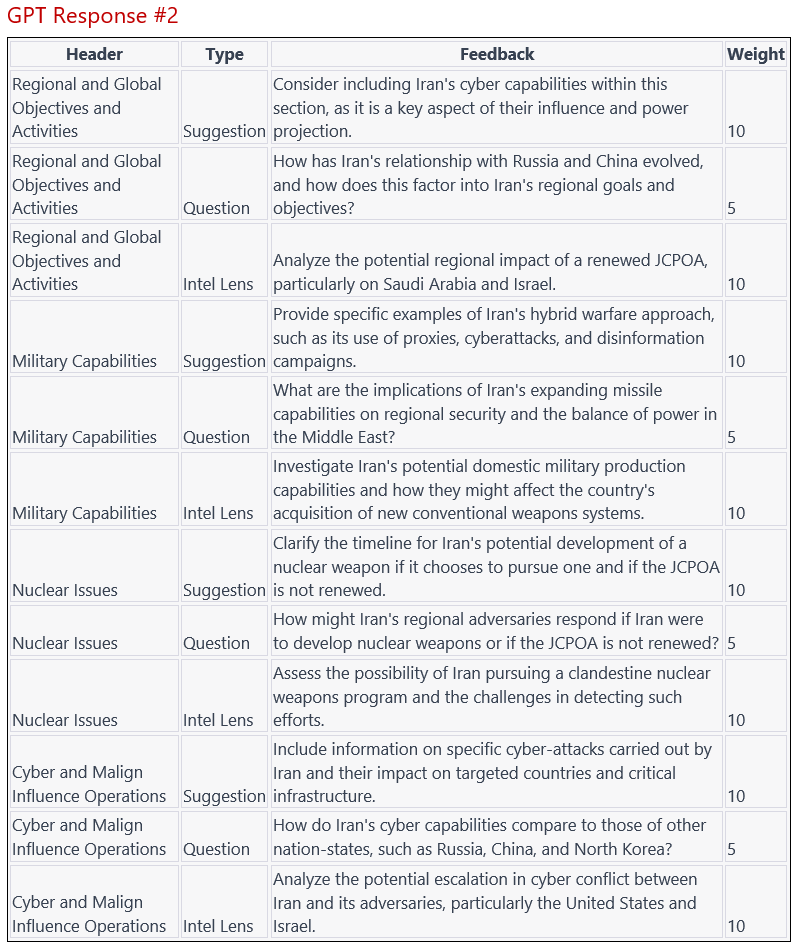
These outputs can help analysts with their projects by evaluating the strengths and weaknesses of intelligence products. We suspect that successors to ChatGPT-4 will refine and approve this capability. IARPA’s REASON project, a research project designed to help analysts’ reasoning with AI systems, is one contemporary initiative to do this.
The Implications for Workforce Development and Future AI Models
Like other information-centric professions such as journalism and law, intelligence practitioners have realized that AI has the potential to disrupt and change how they do their jobs. Four years ago, the intelligence community laid out its own strategy for implementing AI. What is surprising is how fast the technology is improving: Open AI already has plans for enhancing GPT-4, and other vendors are releasing previously restricted tools. The capabilities of the technology to help analysts as we have described above and the improvements of the technology to come suggest a few implications.
First, analysts will need to get more comfortable teaming with AI. Specifically, analysts need a solid grasp of large language models and algorithms, focusing on some of the data biases we have discussed in this article, like data poisoning and the distortion of model outputs based on misinformation. They will also need to hone their prompt engineering skills. Basic data science literacy skills are already important and will become more important in the coming decade. Fortunately, there are ample opportunities to learn and experiment with LLMs for non-tech-savvy users. In a leaked Google memo, one employee noted that experimentation with AI “has dropped from the total output of a major research organization to one person, an evening, and a beefy laptop.”
Second, analytic managers will also need to be aware of how AI will affect how analysts think. In a prescient 2013 article, intelligence scholar Michael Landon-Murray noted that digitization of society is fundamentally rewiring how intelligence analysts think and, in the process, shortening their attention spans. Similarly, the implementation of AI assistants could have the negative side effect of decreasing analysts’ willingness to seek out information in the traditional modes by looking up the answer directly at the source.
Third, there is an inherent danger that systems may simply reinforce modes of thought and analysis as a greater percentage of content of all sorts is produced by LLMs and fed back into them as training data. This risks further weakening analytic skills and creating opportunities for adversaries to achieve strategic surprise.
Last, specialized AI models will be developed by domain. The more specialized the training data fed to AI models, the more useful the output. It is true that the characteristics of intelligence might be different from those of law and from systems being developed for specific domains like finance. A recent model was built using data from the Dark Web. Nonetheless, the general principle of tailoring training data to specific domains remains a valuable approach for enhancing the performance of AI models. Palantir’s AI Platform is a good example of this with implications for defense and military organizations.
The rapid advancement of AI technologies is shaping professions across numerous industries with new systems emerging at a rate professionals might find difficult to keep up with. In intelligence, it is easy to imagine agencies developing innovative technologies with their own models trained on curated data, including classified information. With this changing landscape, ChatGPT is just another technology to which the intelligence community must intelligently adapt.


{kind=link}
{kind=link}